💬 JPA N+1 문제와 페이징, 둘 다 잡으려다 딜레마에 빠졌다
스프링 부트 기반의 음식 주문 관리 플랫폼 프로젝트 중, 가게 검색 기능에서 이 두 가지 난제를 동시에 마주했습니다.
1. 프로젝트 상황 및 초기 목표
Stack: Spring Boot, Spring Data JPA, QueryDSL, PostgreSQL
Domain: Store (1) : Menu (N) (가게와 메뉴는 1:N 관계)
Goal: 가게 목록을 조회하되,
- 연관된
Menu정보도 함께 가져와야 한다 (N+1 문제 방지). - 사용자 경험을 위해 반드시 페이징(
offset,limit)이 적용되어야 한다.
1-1. 초기 접근
처음엔 단순하게 생각했다.
“QueryDSL의 fetchJoin()으로 N+1을 잡고, offset().limit()으로 페이징을 걸면 되지 않을까?”
// 초기 시도: 페이징 처리, fetchJoin 사용
List<StoreResponseDto> content = queryFactory
.select(StoreResponseDto.qConstructor(store, menu))
.from(store)
.leftJoin(menu).on(menu.store.eq(store)).fetchJoin() // ⬅️ N+1 해결
.offset(pageable.getOffset()) // ⬅️ 페이징
.limit(pageable.getPageSize())
.distinct()
.fetch();하지만 이 코드는 N+1을 해결하는 대신, 페이징을 망가뜨렸다.
1-2. 문제의 데이터

카테시안 곱 발생 – Menu 기준으로 데이터가 조회되어, Store 정보가 메뉴 개수만큼 중복되어 나타난다.
2. 이슈 : fetchJoin과 페이징의 충돌
2-1. 카테시안 곱(Cartesian Product) 발생
Store와 Menu처럼 OneToMany 관계에서 fetchJoin을 사용하면, 데이터베이스 단에서 카테시안 곱(Cartesian Product)이 발생한다.
예를 들어, 'A 가게'에 '메뉴'가 10개 있다면, 조회 결과는 'A 가게' 1개가 아니라, ('A 가게'-'메뉴1'), ('A 가게'-'메뉴2'), ..., ('A 가게'-'메뉴10')처럼 10줄의 데이터로 뻥튀기가 된다.
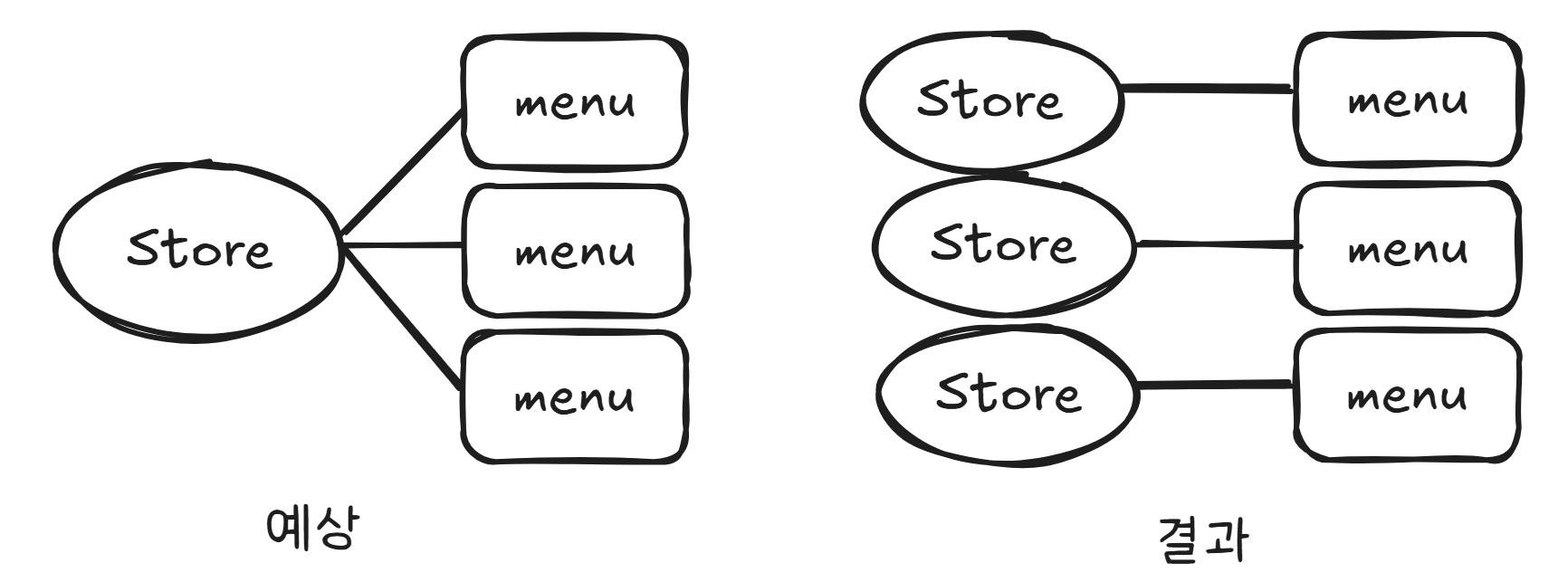
2-2. 문제점
1. DB 레벨 페이징의 실패
데이터베이스는 뻥튀기된 결과(중복된 Store 포함)를 기준으로 LIMIT을 적용된다.
만약 LIMIT 10 (페이지 사이즈 10)을 걸었다면, 우리는 Store 10개를 원했지만 실제로는 'A 가게'의 메뉴 10개만 받고 쿼리가 종료될 수 있습니다. 즉, 페이징이 Store 기준이 아닌, 뻥튀기된 row 기준으로 동작한다.
2. (더 무서운) 메모리 부하와 OOM 위험
JPA 구현체인 Hibernate는 이 문제를 감지된다. (로그에 HHH000104: firstResult/maxResults specified with collection fetch... 경고가 뜹니다.)
Hibernate는 DB 레벨 페이징이 불가능하다고 판단하면, 일단 LIMIT과 OFFSET을 무시하고 카테시안 곱이 발생한 모든 데이터를 애플리케이션 메모리로 로드한다
그리고 메모리 상에서 중복을 제거하고 페이징 처리를 시도한다.
만약 Store가 1만 개, Menu가 평균 10개라면, 10만 건의 데이터를 DB에서 조회해 애플리케이션 메모리에 올리는 것입니다. 페이징을 적용한 의미가 사라지고, 대량 데이터 조회 시 메모리 과부하(OOM)로 이어질 수 있는 치명적인 이슈이다.
3. 이슈 해결을 위한 시도
방법 1: Fetch Join 제거 (일반 Join 사용)
Fetch Join을 빼고, 일반 Join (혹은 Lazy Loading)으로 처리하는 것이다.
- 장점:
Store기준으로 페이징이 DB 레벨에서 정확하게 작동한다. - 단점: N+1 문제가 재발, 조회된
Store가 10개라면, 각Store의Menu를 사용할 때마다 10번의 추가 쿼리가 발생한다. (총 1+10=11번 쿼리)
방법 2: @BatchSize로 N+1 완화
첫 번째 방법(Lazy Loading)의 N+1 문제를 보완하는 방법이다. Store 엔티티의 Menu 컬렉션에 @BatchSize 어노테이션을 추가한다.
@Entity
public class Store {
// ...
@OneToMany(mappedBy = "store")
@BatchSize(size = 100) // ⬅️ 추가
private List<Menu> menus = new ArrayList<>();
}- 작동 방식: (방법 1처럼)
Store를 먼저 조회한 후,Menu가 필요한 시점(Lazy Loading)에 N번의 쿼리가 나가는 대신,@BatchSize에 설정된 수(예: 100)만큼StoreID를 묶어IN절 쿼리로 한 번에 조회한다. - 장점: 개발이 매우 간편하고, (어노테이션 한 줄). N+1 쿼리 횟수를 100번 → 1번 (혹은 N/100번)으로 크게 줄여 성능을 개선한다.
- 단점:
fetchJoin처럼 쿼리 한 번으로 모든 데이터를 가져오는 것은 아니며, 본질적으로 쿼리 횟수가 증가한다. 조회 수가 적을 때는 유효하지만, 근본적인 해결책은 아니다
방법 3: 쿼리 2단계로 분리
Store 목록을 페이징하는 쿼리와, 연관된 Menu까지 fetchJoin하는 쿼리를 2단계로 분리하는 것이다.
// 1. 1차 쿼리: 페이징을 적용하여 Store ID만 조회
List<UUID> storeIds = queryFactory
.select(store.id)
.from(store)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// 2. 2차 쿼리: ID 목록으로 IN절 + fetchJoin
List<StoreResponseDto> content = queryFactory
.select(StoreResponseDto.qConstructor(store, menu))
.from(store)
.leftJoin(menu).on(menu.store.eq(store)).fetchJoin()
.where(store.id.in(storeIds)) // ⬅️ IN 절 사용
.fetch();4. 최종 해결 방법: 쿼리 분리
4-1. 각 방법의 장단점 비교
| 최적화 기법 | 장점 | 문제점 |
|---|---|---|
| 일반 Join (Lazy Loading) | 페이징은 정확함 | N+1 문제 발생 |
| @BatchSize | 개발이 간편, N+1 완화 | N+1이 근본적으로 해결되진 않음. (단기적 처방) |
| 쿼리 분리 | 정확한 DB 페이징 + N+1 완벽 해결 | 구현 로직이 다소 복잡 |
조회 건수가 수천·수만 개로 늘어나는 대규모 환경을 가정 시
@BatchSize나 (경고가 뜨는) fetchJoin + 페이징은 결국 Hibernate의 메모리 로딩 방식에 의존적이므로 근본적인 한계가 있다.
반면, 쿼리를 2단계로 분리하는 전략은 완전히 DB 기반으로 동작한다.
- DB의
LIMIT기능을 활용해 정확한StoreID 목록을 가져오고, IN절과fetchJoin으로 연관 엔티티를 N+1 없이 로딩한다.
이 방식은 대량의 데이터를 메모리에 한꺼번에 로드할 필요가 없어 시스템 안정성을 보장하며, 데이터 규모가 커져도 성능 편차가 적고 안정적이다.
4-2. 최종 데이터

Store 기준으로 페이징이 올바르게 동작하며, Menu 정보도 정상적으로 함께 조회된다.
5. 결론
JPA의 fetchJoin은 강력하지만, 페이징과 만났을 땐 '어떻게' 동작하는지(메모리 로딩)를 아는 것이 중요했다. N+1과 페이징을 모두 잡아야 한다면, 쿼리를 분리하는 것이 가장 확실한 방법이다.